DR Strategies with Confluent/Kafka
Kafka is a distributed system, and it comes with high data durability. For a Kafka cluster with RF=3, RF = Replication Factor, for every active copy, there are two additional copies of the data. Active copy is called leader and additional copies are called followers.
There are many approaches to achieve high availability (HA) and Disaster Recovery (DR) for the kafka deployments.
- Mirror Maker 2 (MM2)
- Confluent Replicator
- Cluster Linking
- Multi-Region Cluster (MRC)
- Object Store Based Backup/Restore
Connect Based Kafka Replication
Mirror Maker 2 (MM2), Confluent Replicator and Cluster Linking based approach is to replicate data from one kafka cluster to another. There are not so many significant differences between MM2 and Confluent Replicator, as both are based on Kafka Connect. Both MM2 and Confluent Replicator need additional resources in terms of Connect Cluster nodes.
Server based Kafka Replication
Cluster Linking on the other hand is very unique as it enables byte by byte replication from Kafka broker from one cluster to another. Messages from source topics are mirrored precisely onto destination topics. This makes failover very seamless, as offsets, ACLs, Schemas are preserved from source to destination. There are no additional resources needed to run Cluster Linking as it is built in as part of the Confluent Server.
Multi-Region Cluster is another way to achieve HA and DR where a single cluster is stretched across the regions and clients get the impression that they are talking to the same cluster even if the disaster is stuck. MRC enables spanning the single kafka topic across regions, with the help of leaders, followers and observers. Observers can be set to have sync or async policies, depending on the RPO/RTO requirements.
Poor Man’s DR : High RPO:RTO
If an organization has high RPO and RTO requirements, like up to 24 hours, then one can choose the approach in which they can use object store buckets as backup stores. In this approach, all kafka data is egressed into Object Store buckets using Sink Connector from a Kafka cluster and if the disaster is stuck then, using a source connector the kafka cluster in the DR region is hydrated.
Key to remember is that this workload has a high RTO and RPO. For low RPO/RTO use cases, this would not work well.
Above mentioned approach would also work with Confluent Cloud and not just the Confluent platform. Once the disaster is struck, infrastructure can be set up for self-managed or managed kafka service and connectors can be set up to hydrate the DR region kafka clusters. Of course this option comes with a trade off, where we want to save on provisioning large amounts of kafka resources and which will not be used unless the disaster is stuck.
Diagrams below illustrate the workflow.
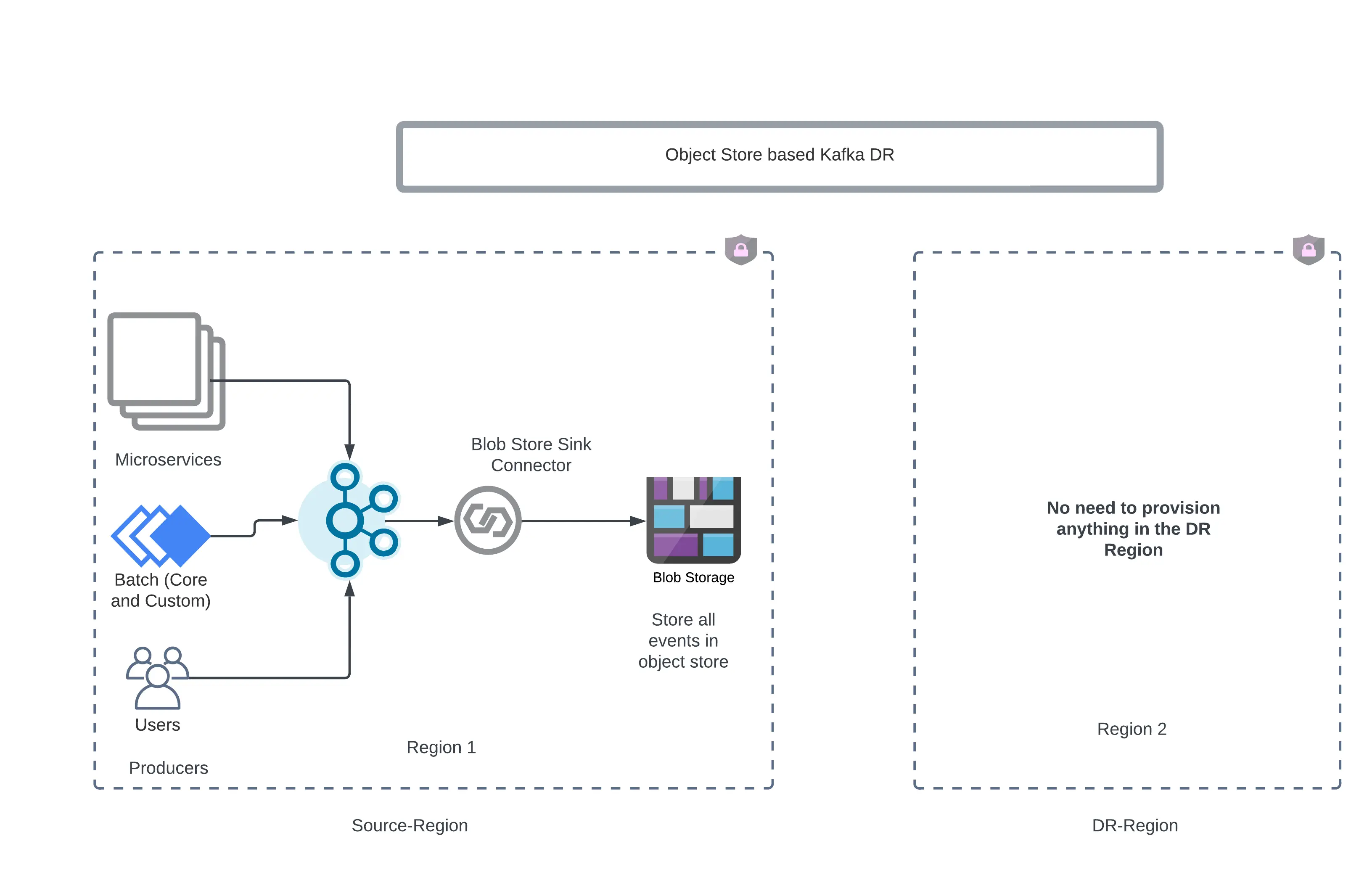
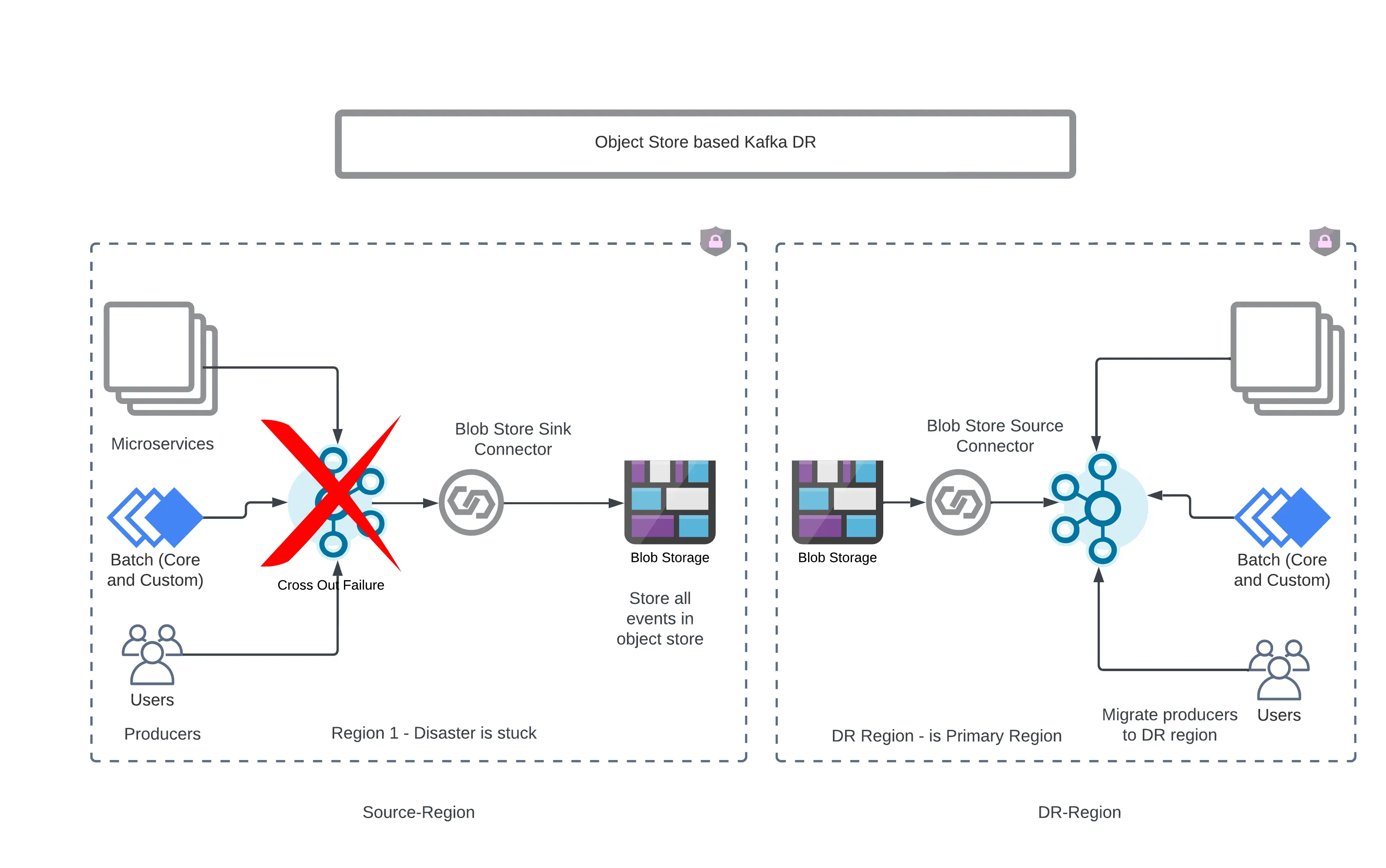
Confluent supports all three major clouds as object store destinations (sink) and sources.
- Amazon S3 Source Connector for Confluent Platform | Confluent Documentation
- Azure Blob Storage Source Connector for Confluent Platform | Confluent Documentation
- Backup and Restore Google Cloud Storage Source Connector for Confluent Platform | Confluent Documentation
It becomes very intuitive at this point, given the conditions of high RPO and RTO, about 24 hours, the above method is very appealing when intent is to have DR in place but cost due to Confluent clusters at the destination, data transfer across clusters and data retention are major factors. Clearly this is not going to be feasible if RPO and RTO are less and the benefits of the cost savings not significant, then using one of the replicating technologies is a better choice.
Further reading: Disaster Recovery in the Confluent Cloud - Whitepaper.